Have you ever fallen into a void after finishing a movie and tried to find similar ones? After a movie that impressed me, I immediately try to find alternatives. If we really enjoy working with data and are good at algorithms, why not build our own system?
We used the cosine similarity metric to achieve our results. I think I’ve been obsessed with it lately. I use it especially when I study on text similarities. In this study, we are going to use the method I mentioned. Let’s dive into it.
Cosine similarity measures the similarity between two vectors and is the cosine of the angle between two vectors. The smaller the angle between two vectors, the more similar they are to each other.
Consider two vectors, x and y. We can calculate the cosine similarity between the vectors as follows:
\(cos(\theta) = \frac{x.y}{||x||||y||} = \frac{\sum_{i=1}^{n}x_iy_i}{\sqrt{\sum_{i=1}^{n}x_i^2}\sqrt{\sum_{i=1}^{n}y_i^2}}\)
See how it’s calculated with a simple example.
\(x.y = 3*3 + 4*4 + 1*4 + 0*8 = 29\)
\(||x|| = \sqrt{3^2 + 4^2 + 1^2 + 0^2} = 5.09902\)
\(||y|| = \sqrt{3^2 + 4^2 + 4^2 + 8^2} = 10.24695\)
\(cos(x,y) = cos(\theta) = \frac{29}{5.09902*10.24695} = 0.5550303\)
Remember: The smaller the angle between two vectors, the more similar they are to each other. So, if the angle between vectors is zero degrees, then the cosine similarity value is 1, which means the two vectors are similar or relevant. The similarity can be any value in the range [−1,1]. In addition to this, the cosine distance is as:
\(Cosine\ Distance\ =\ 1\ -\ Cosine\ Similarity\)
Cosine similarity can also be calculated with the help of the {lsa} package.
as.numeric(lsa::cosine(x,y))[1] 0.5550303So, how can similarity be calculated when it comes to texts? Let me give you an example.
text1 <- "I am learning R programming language"
text2 <- "I am learning Python programming language"We can create two vectors with the word frequencies corresponding to each other as follows:
# I, am, learning, R, Python, programming, language
text1_n <- c(1,1,1,1,0,1,1)
text2_n <- c(1,1,1,0,1,1,1)
as.numeric(lsa::cosine(text1_n,text2_n))[1] 0.8333333We can move on to building a movie recommender system. The data to be used in the study will be obtained by web scraping from IMDB.
The following steps can be followed:
Menu/Browse Movies by Genre
Popular Movies by Genre/Sci-Fi (Scroll down to see)
Focus on last URL. The value you see as 1 next to start will increase by 50 each time you switch to the next page. In fact, you do not encounter this URL at first, but when you move to the next page, you can obtain this URL and edit the first page yourself. The movie list starts with the value you type in the value to the right of start.
I want to get the first 100 URLs in the list sorted by popularity.
URLs need to be created first.
urls <- str_c(
"https://www.imdb.com/search/title/?title_type=feature&genres=sci-fi&start=",
seq(1,5000,50),
"&explore=genres&ref_=adv_nxt"
)
urls[c(1,length(urls))][1] "https://www.imdb.com/search/title/?title_type=feature&genres=sci-fi&start=1&explore=genres&ref_=adv_nxt"
[2] "https://www.imdb.com/search/title/?title_type=feature&genres=sci-fi&start=4951&explore=genres&ref_=adv_nxt"We are going to get the titles and descriptions of the movies using a for loop. See the examples below for the first page.
firstURL <- urls[1]
title <- read_html(firstURL) %>%
html_nodes("div.lister-item-content h3.lister-item-header a") %>%
html_text()
head(title)[1] "Nope"
[2] "Prey"
[3] "Samaritan"
[4] "DC League of Super-Pets"
[5] "Thor: Love and Thunder"
[6] "Everything Everywhere All at Once"description <- read_html(firstURL) %>%
html_nodes("p.text-muted") %>%
html_text() %>%
.[c(FALSE,TRUE)] %>%
gsub("[\n]", "", .)
head(paste0(substr(description,1,100),"..."))[1] "The residents of a lonely gulch in inland California bear witness to an uncanny and chilling discove..."
[2] "The origin story of the Predator in the world of the Comanche Nation 300 years ago. Naru, a skilled ..."
[3] "A young boy learns that a superhero who was thought to have gone missing after an epic battle twenty..."
[4] "Krypto the Super-Dog and Superman are inseparable best friends, sharing the same superpowers and fig..."
[5] "Thor enlists the help of Valkyrie, Korg and ex-girlfriend Jane Foster to fight Gorr the God Butcher,..."
[6] "An aging Chinese immigrant is swept up in an insane adventure, where she alone can save the world by..."df <- data.frame(
title = title,
description = description
)| title | description |
|---|---|
| Nope | The residents of a lonely gulch in inland California bear witness to an uncanny and chilling discovery. |
| Prey | The origin story of the Predator in the world of the Comanche Nation 300 years ago. Naru, a skilled warrior, fights to protect her tribe against one of the first highly-evolved Predators to land on Earth. |
| Samaritan | A young boy learns that a superhero who was thought to have gone missing after an epic battle twenty years ago may in fact still be around. |
| DC League of Super-Pets | Krypto the Super-Dog and Superman are inseparable best friends, sharing the same superpowers and fighting crime side by side in Metropolis. However, Krypto must master his own powers for a rescue mission when Superman is kidnapped. |
| Thor: Love and Thunder | Thor enlists the help of Valkyrie, Korg and ex-girlfriend Jane Foster to fight Gorr the God Butcher, who intends to make the gods extinct. |
| Everything Everywhere All at Once | An aging Chinese immigrant is swept up in an insane adventure, where she alone can save the world by exploring other universes connecting with the lives she could have led. |
Creating the dataset…
master <- data.frame()
for(i in seq_along(urls)){
title <- read_html(urls[i]) %>%
html_nodes("div.lister-item-content h3.lister-item-header a") %>%
html_text()
description <- read_html(urls[i]) %>%
html_nodes("p.text-muted") %>%
html_text() %>%
.[c(FALSE,TRUE)] %>%
gsub("[\n]", "", .)
master <- master %>%
bind_rows(
data.frame(
title = title,
description = description
)
)
#print(i)
Sys.sleep(1)
}A dataset should be examined after it is created, but in this work I ignore this step. Ultimately, we have 5000 movies.
Finally we can move on to the cosine similarity calculation. The {widyr} package can be used to calculate it. The 2 packages shown below will be used.
We are going to calculate cosine similarity based on two methods: Word Frequencies and TF-IDF.
master2 <- master %>%
unnest_tokens(output = "word", input = "description") %>%
anti_join(get_stopwords()) %>%
count(word, title) %>%
bind_tf_idf(word, title, n)Cosine Similarity - Word Frequencies:
Cosine Similarity - TF-IDF:
TF-IDF stands for Term Frequency-Inverse Document Frequency, and it’s intended to measure how important a word is to a document in a collection or corpus.
i: term (word),
j: document (set of words),
N: count of corpus (the total document set)
tf(i,j) = count of i in j / number of words in j
df(i) = occurrence of i in documents
idf(i) = log(N/(df + 1))
tf-idf(i,j) = tf(i,j) * log(N/(df + 1))
I used Minority Report, of the Sci-Fi genre as the item to be used for cosine similarity calculations when recommending the top 10 movies.
Based on word frequency:
| item | similarity_freq |
|---|---|
| Minority Report—Judge Dredd | 0.3077935 |
| Cyborg 2087—Minority Report | 0.2766858 |
| Minority Report—Omega Cop | 0.2601330 |
| Le dernier combat—Minority Report | 0.2545139 |
| Para iz buduschego—Minority Report | 0.2445580 |
| Minority Report—Eternity | 0.2445580 |
| Minority Report—Maayavan | 0.2433321 |
| Minority Report—Knights | 0.2433321 |
| Minority Report—Narcopolis | 0.2391824 |
| Minority Report—Trudno byt bogom | 0.2369396 |
The title with the closest similarity was Judge Dredd based on word frequency.
Based on TF-IDF:
| item | similarity_tf_idf |
|---|---|
| Minority Report—Time Frame | 0.2416788 |
| Minority Report—Strange Behavior | 0.1993392 |
| Minority Report—Outpost 37 | 0.1971800 |
| Minority Report—Resident Evil | 0.1873535 |
| Minority Report—Im Stahlnetz des Dr. Mabuse | 0.1752203 |
| Kidô keisatsu patorebâ: The Movie 2—Minority Report | 0.1744674 |
| Minority Report—In the Shadow of the Moon | 0.1643750 |
| Minority Report—Time Under Fire | 0.1642217 |
| Minority Report—Judge Dredd | 0.1626650 |
| Minority Report—Maayavan | 0.1608787 |
The title with the closest similarity was Time Frame based on TF-IDF.
df_wf %>%
ggplot(aes(x = reorder(item, similarity_freq), y = similarity_freq, fill = similarity_freq)) +
geom_col() +
ggthemes::theme_fivethirtyeight() +
theme(legend.position = "none") +
scale_fill_gradient(low = "orange", high = "red") +
coord_flip() +
labs(title = "Word Frequency") -> g1
df_tfidf %>%
ggplot(aes(x = reorder(item, similarity_tf_idf), y = similarity_tf_idf, fill = similarity_tf_idf)) +
geom_col() +
ggthemes::theme_fivethirtyeight() +
theme(legend.position = "none") +
scale_fill_gradient(low = "orange", high = "red") +
coord_flip() +
labs(title = "TF-IDF") -> g2gridExtra::grid.arrange(g1,g2,ncol=2)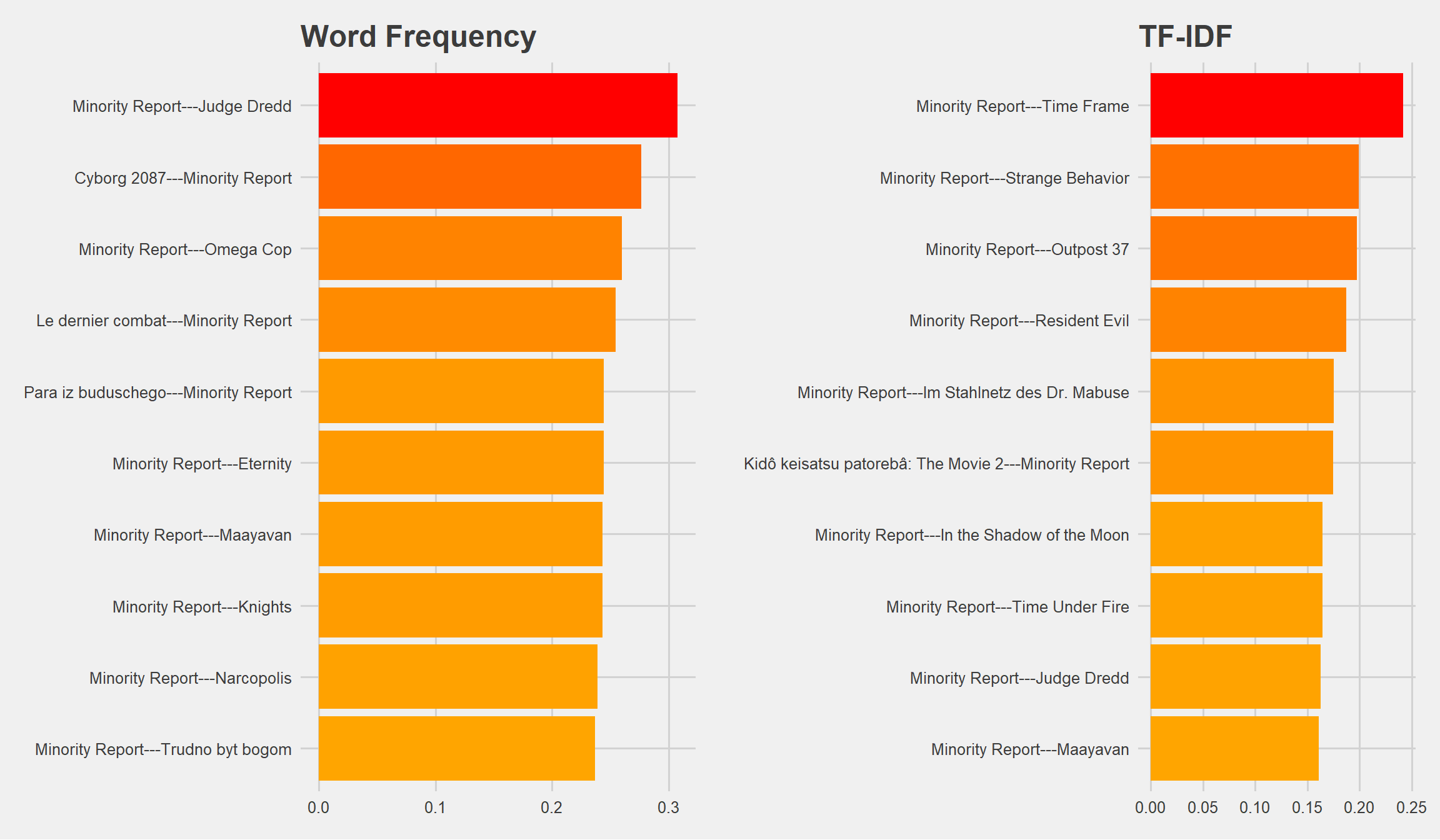
| title | description |
|---|---|
| Minority Report | In a future where a special police unit is able to arrest murderers before they commit their crimes, an officer from that unit is himself accused of a future murder. |
| Judge Dredd | In a dystopian future, Joseph Dredd, the most famous Judge (a police officer with instant field judiciary powers), is convicted for a crime he did not commit and must face his murderous counterpart. |
| Time Frame | What if you were eleven hours away from being executed for a murder you didn’t commit, and the only way to save yourself was to go back in time, and commit the murder? |
If everything is clear so far, you can do more using your imagination. These studies don’t work without story and imagination.