Brownian hareketi (Brownian motion), toz parçacıkları gibi büyük parçacıkların akışkan içerisinde sıvı ya da gaz molekülleri gibi daha küçük parçacıklarla çarpışması sonucu oluşan rastlantısal harekettir. Brown hareketi literatürde Wiener süreci olarak da bilinmektedir. Brownian hareket sürecinin en basit özel durumu standart Brownian hareket sürecidir.
Yukarıda bahsedilen standart Brownian hareket süreci negatif değerler de alabildiği için uygulamamıza uymayacaktır. Bu noktada devreye geometrik Brownian hareket süreci giriyor. Bu süreçte getiriler log-normal dağılımlı olduğu için negatif durum ortadan kaldırılıyor. Bunun yanında log-normal dağılım ile kalın kuyruk durumu ve çarpıklık dikkate alınmış oluyor.
Geometrik Brownian hareket sürecine uyan bir finansal varlığın fiyatındaki değişim özellikle finansal modellemede \(dS_t = \mu S_t d_t + \sigma S_t dW_t\) (stokastik diferansiyel denklem) olarak ifade edilmektedir. Bu denklem aşağıdaki gibi yeniden yazılabilir:
\(dlogS_t = (\mu - \frac{\sigma^2}{2})dt + \sigma dW_t\)
\(dt\) zaman aralığında değişim olan \(dW_t = \epsilon \sqrt{dt}\)’dir. Burada, \(W_t\)’deki değişme miktarı epsilon ile geçen sürenin karekökünün çarpımı; \(\epsilon \sim N(0,1)\)’dir ve \(\epsilon\) ortalaması 0, standart sapması 1 olan standart normal dağılım tablosundan üretilen rastsal rakamdır.
Sonuç olarak kullanacağımız denklem (Ito Lemma):
\(S_t = S_0 exp((\mu - \frac{1}{2}\sigma^2)t + \sigma W_t)\) olacaktır.
\(S_0:\) başlangıç fiyatı,
\(\mu:\) beklenen getiri (drift, sürüklenme),
\(\sigma:\) volatilitedir.
Uygulamayı şöyle tasarladım:
\(\mu\) ve \(\sigma\)’nın her bir yıl için hesaplanması ve test edilecek yıl için regresyon modeli kullanılarak uygun \(\mu\) ve \(\sigma\) değerinin kullanılması.
Her bir yıl için 1000 adet simüle değerin oluşturulması ve ortalamasının alınması.
2018, 2019, 2020 ve 2021 için test edilmesi.
Alternatif yöntem ile karşılaştırmanın yapılması.
Investing’ten aldığım verilere (post4.xlsx) GitHub hesabımdan ulaşabilirsiniz.
Geometrik Brownian motion’a ait fonksiyonu oluşturalım.
gbmFunc <- function(nsim,t,mu,sigma,S0,nwd){ # kullanıcı tarafından girilecek değerler
gbm <- matrix(ncol = nsim, nrow = t)
# simülasyon sayısı kadar sütun; gün sayısı kadar satır
for(i in 1:nsim){ # i: initial (başlangıç)
gbm[1,i] <- S0 # gbm matrisinin ilk satırları girilen başlangıç fiyatı olacak
for(d in 2:t){ # d: day (gün); ilk satır belli olduğu için ikinci satırdan başlayacak
epsilon <- rnorm(1) # epsilon ortalaması sıfır ve standart sapması 1 idi
dt <- 1 / nwd # nwd: number of working days (iş günleri sayısı)
gbm[d,i] <- gbm[(d-1),i] * exp((mu - sigma**2 / 2) * dt + sigma * epsilon * sqrt(dt))
}
}
return(gbm)
}
Tarihsel olarak \(\mu\) ve \(\sigma\) değerlerine bakalım.
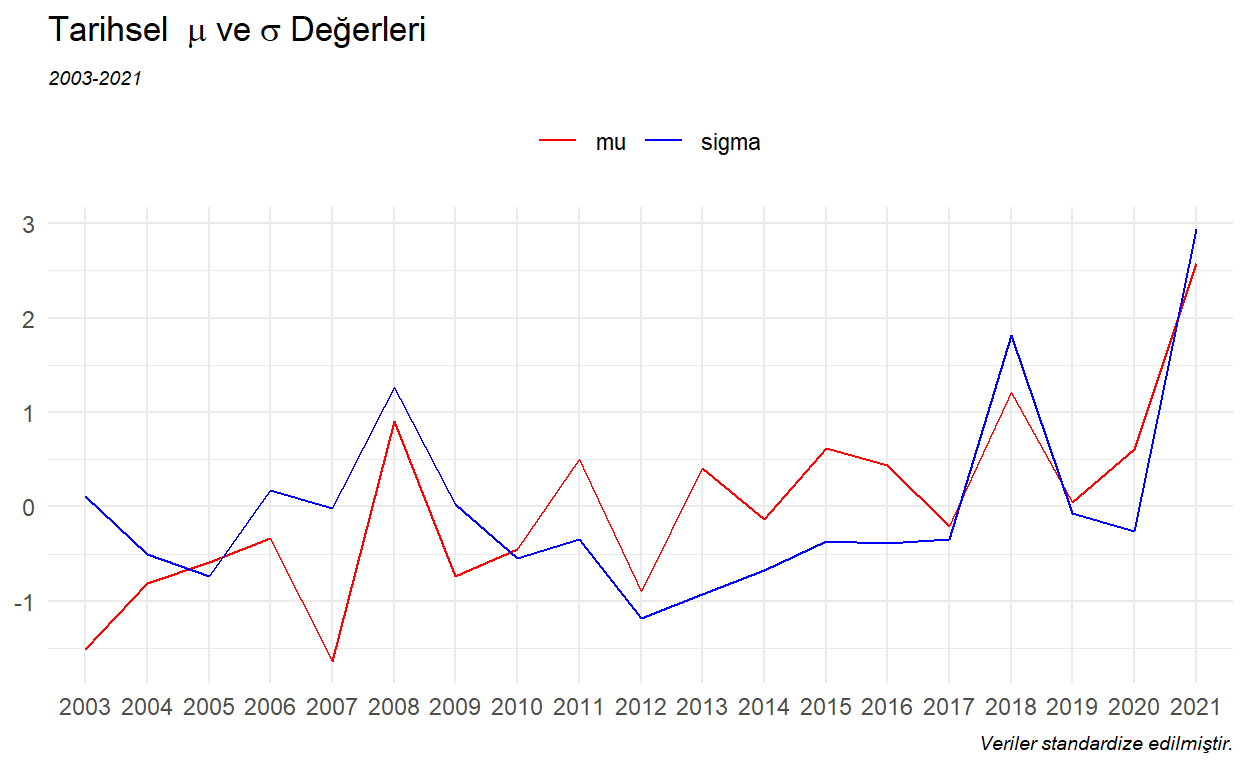
Her yıl için geçmiş 5 seneyi dikkate alarak \(\mu\) ve \(\sigma\) değerlerini tahmin edelim.
musigma_hist$pred_mu <- NA
musigma_hist$pred_sigma <- NA
target <- 2018:2021
for(j in 1:length(target)) {
m_df <- musigma_hist %>%
filter(year < target[j] & year >= target[j] - 5) %>%
mutate(t = seq(1, nrow(.), 1))
model_mu <- lm(mu ~ 0 + t, data = m_df)
model_sigma <- lm(sigma ~ 0 + t, data = m_df)
# t: trend
pred_mu <- predict(model_mu, newdata = data.frame(t = nrow(m_df) + 1))
pred_sigma <- predict(model_sigma, newdata = data.frame(t = nrow(m_df) + 1))
musigma_hist[which(musigma_hist$year == target[j]), ][5] <- as.numeric(pred_mu)
musigma_hist[which(musigma_hist$year == target[j]), ][6] <- as.numeric(pred_sigma)
}
Tahmin ettiğimiz değerlerin başarısını RMSE metriği ile ölçeceğiz. Kök Ortalama Kare Hata da diyebileceğimiz Root Mean Square Error, tahmin hatalarının (residuals) standart sapmasıdır. RMSE için regresyon çizgisinin etrafındaki yoğunlaşmayı ölçüyor da diyebiliriz.
\(RMSE = \sqrt{\frac{\sum_{i=1}^{N}(Tahmin_i-Gerçek_i)^2}{N}}\)
rmse <- function(predicted,actual){
rmse_value <- sqrt(mean((predicted-actual)^2))
return(rmse_value)
}
rmse_df <- data.frame(
"year" = 2018:2021,
"rmse_avg" = NA
)
Tüm yılları hesaplayalım.
sim_master <- data.frame()
gbmdf_master <- data.frame()
for(k in 1:length(target)){
df_target <- df %>%
filter(year == target[k])
sim_target <- gbmFunc(nsim = 1000,
t = nrow(df_target),
mu = as.numeric(musigma_hist[(j+15),5]),
sigma = as.numeric(musigma_hist[(j+15),6]),
S0 = as.numeric(df_target[1,2]),
nwd = nrow(df_target)) %>%
as.data.frame() %>%
mutate("simAvg" = rowMeans(.)) %>%
mutate(rn = 1:nrow(.), .before = V1) %>%
cbind(df_target[,2]) %>%
mutate("year" = target[k], .after = rn)
sim_master <- sim_master %>% bind_rows(sim_target)
gbmdf_target <- as.data.frame(sim_target) %>%
pivot_longer(!c(rn,year), names_to = "sim", values_to = "value")
gbmdf_master <- gbmdf_master %>% bind_rows(gbmdf_target)
rmse_df$rmse_avg[k] <- rmse(predicted = sim_target$simAvg, actual = sim_target$close)
}

2018-2021 yılları için yaptığımız simülasyonlardan elde ettiğimiz RMSE değerleri aşağıdaki gibidir.
| year | rmse_avg |
|---|---|
| 2018 | 1.3661915 |
| 2019 | 0.4085097 |
| 2020 | 1.3118926 |
| 2021 | 2.1905821 |
Bundan sonra asıl konumuza giriş yapacağız.
Tüm simüle değerlerin ortalamasını almak yerine kümeleme algoritması kullanıp aynı kümeye düşen simüle değerlerin ortalamasını alsaydık performans ne olurdu?
Kümeleme için aşağıdakileri kullanacağız:
Kümeleme algoritması Hierarchical
Bağlantı yöntemi Ward
Uzaklık ölçütü Euclidean
Kümeleme Algoritması Hierarchical (Hiyerarşik)
Hiyerarşik kümeleme yöntemleri, ayrı ayrı ele alınan kümelerin aşamalı olarak birleştirilmesi veya bir ana küme olarak ele alınarak aşamalı olarak alt kümelere ayrılması esasına dayanır.
Bağlantı Yöntemi Ward
Ward, agglomerative nesting denilen birleştirici kümeleme yöntemidir. Bu yöntemde amaç, bir küme oluşturabilmek için toplam varyanstaki artışların minimize edilmesidir. Bunun için küme içindeki kareli toplamlar kullanılır ve bu değerin minimize edilmesi esas alınır.
\(ESS = \sum_{g=1}^{G} \sum_{i=1}^{n_g} \sum_{j=1}^{p} (x_{ij}^g - \overline{x}_j^g)^2\)
\(G:\) Kümelerin sayısı
\(n_g:\) g. küme içindeki gözlem sayısı
\(x_{ij}^g:\) g. küme içindeki i. gözlemin j. niteliğinin değeri
\(\overline{x}_j^g:\) g. küme içindeki j niteliğinin ortalaması
Uzaklık ölçütü Euclidean (Öklid)
Bu uzaklık boyutlu uzayda Pisagor teoreminin bir uygulamasıdır. A noktası \((x_1,y_1)\); B noktası \((x_2,y_2)\) olsun.
A ve B noktaları arasındaki Öklid uzaklığı:
\(d(A,B) = \sqrt{(x_1 - x_2)^2 + (y_1 - y_2)^2}\)
Algoritmayı uygulama aşamasına geçebiliriz. Önceki testlerimizden farklı olarak burada simülasyonu biraz daha geriden başlatacağız. Çünkü test edilecek yıla ait değerlerin henüz gerçekleşmediğini varsayarsak, önceki yılın bir bölümünü alıp burada gerçekleşen değerleri bir kümeye dahil etmemiz gerekir. Bunun için de test edilecek yıldan bir önceki yılın son 100 iş gününü alabiliriz. Bu durumda aşamaları şöyle sıralayabiliriz: Test edilecek yıldan bir önceki yılın son 100 iş gününü al, burayı simüle et, simüle değerleri kümelere ayır, 100 gün için gerçekleşen değerleri bir kümeye dahil et ve buradan seçilen kümeleri kullanarak test edilecek yılın değerlerini bul. 100 iş gününü seçme nedenim vade uzadıkça tahmin gücünün zayıflayabileceğini dikkate alarak çok geriden başlatıp tahmini kötüleştirmemek; bununla beraber, çok da erken başlatıp zaman serilerini kümelerken kaliteyi düşürmemek.
filter_min <- df %>%
filter(year %in% 2017:2020) %>%
group_by(year) %>%
slice(tail(row_number(), 100)) %>%
filter(date == min(date)) %>%
pull(date)
filter_max <- df %>%
filter(year %in% 2018:2021) %>%
group_by(year) %>%
filter(date == max(date)) %>%
pull(date)
mlsim_master <- data.frame()
joined_clusters_master <- data.frame()
for(m in 1:length(target)){
mldf <- df %>%
filter(date >= filter_min[m] & date <= filter_max[m])
mlsim <- gbmFunc(nsim = 1000,
t = nrow(mldf),
mu = as.numeric(musigma_hist[(m+15),5]),
sigma = as.numeric(musigma_hist[(m+15),6]),
S0 = as.numeric(mldf[1,2]),
nwd = nrow(mldf)) %>%
as.data.frame() %>%
mutate(rn = 1:nrow(.), .before = V1) %>%
cbind(mldf[,2]) %>%
mutate("year" = target[m], .after = rn)
mlsim_master <- mlsim_master %>% bind_rows(mlsim)
mlgbm <- t(scale(mlsim[1:100,-c(1,2)])) # son 100 günü kümelemeye dahil etmeliyiz
mlgbm_dist <- dist(mlgbm, method="euclidean")
fit <- hclust(mlgbm_dist, method="ward.D")
clustered <- cutree(fit, k=50) # 50 adet küme oluşturulmuştur
clustered_tidy <- as.data.frame(as.table(clustered)) %>%
rename("sim"=1,"cluster"=2) %>%
mutate(sim = as.character(sim))
cluster_x <- clustered_tidy %>%
filter(sim == "close") %>%
pull(cluster) %>%
.[[1]]
mldf_2 <- mlsim %>%
pivot_longer(!c(rn,year), names_to = "sim", values_to = "value")
joined_clusters <- mldf_2 %>%
inner_join(clustered_tidy, by = "sim") %>%
filter(cluster == cluster_x) %>%
select(-cluster) %>%
pivot_wider(names_from = "sim", values_from = "value") %>%
mutate("simAvg" = apply(.[,-c(1,2,ncol(.))], 1, function(x) median(x))) %>%
# uç değerlerden etkilenmemek için ortalama yerine medyan (ortanca) kullanıldı
pivot_longer(!c(rn,year), names_to = "sim", values_to = "value")
joined_clusters_master <- joined_clusters_master %>% bind_rows(joined_clusters)
if(m == length(target)){
rmse_df2 <- joined_clusters_master %>%
filter(sim %in% c("simAvg","close")) %>%
pivot_wider(names_from = "sim", values_from = "value") %>%
group_by(year) %>%
summarise("rmse_avg_cluster" = rmse(simAvg,close)) %>%
ungroup() %>%
left_join(rmse_df, by = "year")
}
}

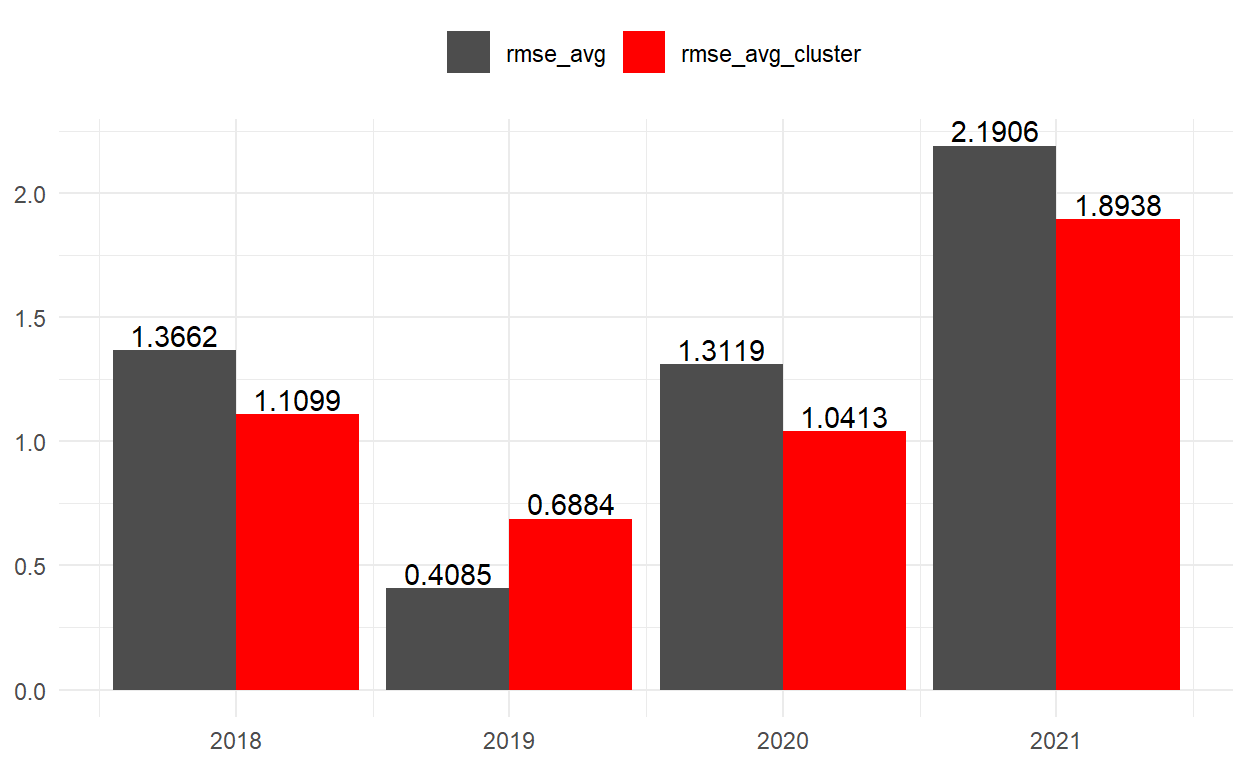
| year | rmse_avg_cluster | rmse_avg |
|---|---|---|
| 2018 | 1.1098768 | 1.3661915 |
| 2019 | 0.6884056 | 0.4085097 |
| 2020 | 1.0413089 | 1.3118926 |
| 2021 | 1.8937623 | 2.1905821 |
Yukarıdaki tablodan ve aşağıdaki grafikten görüleceği üzere RMSE değerlerini tek bir yıl hariç düşürdük ki sıfıra yaklaşması hiç tahmin hatası yapılmadığı anlamına geliyor.
Çalışmada kümeleme algoritmasının simülasyonda faydalı olabileceğine odaklanmak istedim. Burada \(\mu\) ve \(\sigma\) değerlerinin, iş günü sayısının, küme sayısının en uygun şekilde seçimi önem kazanacaktır.
Görsellere ait kodlara aşağıdan ulaşılabilir.
ggplot(df, aes(x = date, y = log(close), group = 1)) +
geom_line() +
theme_minimal() +
theme(axis.title = element_blank(),
plot.title = element_text(face = "bold"),
plot.subtitle = element_text(face = "italic", size = 7),
plot.caption = element_text(face = "italic", size = 7)) +
labs(title = "USDTRY Günlük Değerler",
subtitle = "01.01.2003 - 31.12.2021",
caption = "Değerler logaritmiktir.\nVeriler Investing'ten alınmıştır.")
ggplot(df, aes(x = date, y = logReturn, group = 1)) +
geom_line() +
theme_minimal() +
theme(axis.title = element_blank(),
plot.title = element_text(face = "bold"),
plot.subtitle = element_text(face = "italic", size = 7),
plot.caption = element_text(face = "italic", size = 7)) +
labs(title = "USDTRY Günlük Logaritmik Getiriler",
subtitle = "01.01.2003 - 31.12.2021",
caption = "Veriler Investing'ten alınmıştır.")
musigma_hist %>%
select(-t) %>%
mutate(mu = scale(mu),
sigma = scale(sigma)) %>%
pivot_longer(!year, names_to = "cons", values_to = "val") %>%
ggplot(aes(x = factor(year), y = val, group = cons, color = cons)) +
geom_line() +
theme_minimal() +
theme(axis.title = element_blank(),
plot.subtitle = element_text(face = "italic", size = 7),
plot.caption = element_text(face = "italic", size = 7),
legend.title = element_blank(),
legend.position = "top") +
labs(title = expression("Tarihsel "~mu~"ve"~sigma~"Değerleri"),
subtitle = "2003-2021",
caption = "Veriler standardize edilmiştir.") +
scale_color_manual(values = c("red","blue"))
ggplot(gbmdf_master, aes(x = rn, group = sim)) +
geom_line(data = gbmdf_master %>% filter(!(sim %in% c("simAvg","close"))),
aes(y = value), color = "gray80") +
geom_line(data = gbmdf_master %>% filter(sim == "simAvg"),
aes(y = value), color = "red") +
geom_line(data = gbmdf_master %>% filter(sim == "close"),
aes(y = value), color = "blue") +
facet_wrap(~year, scales = "free") +
theme_minimal() +
theme(axis.title = element_blank(),
plot.title = element_text(face = "italic", size = 7)) +
labs(title = "Kırmızı: Ortalama Simüle, Mavi: Gerçek, Gri: Simüle")
ggplot(joined_clusters_master, aes(x = rn, group = sim)) +
geom_line(data = joined_clusters_master %>% filter(!(sim %in% c("simAvg","close"))),
aes(y = value), color = "gray80") +
geom_line(data = joined_clusters_master %>% filter(sim == "simAvg"),
aes(y = value), color = "red") +
geom_line(data = joined_clusters_master %>% filter(sim == "close"),
aes(y = value), color = "blue") +
facet_wrap(~year, scales = "free") +
theme_minimal() +
theme(axis.title = element_blank(),
plot.title = element_text(face = "italic", size = 7)) +
labs(title = "Kırmızı: Ortalama Simüle, Mavi: Gerçek, Gri: Simüle")
rmse_df2 %>%
pivot_longer(!year, names_to = "rmse_test_type", values_to = "RMSE") %>%
ggplot(aes(x = year, y = RMSE, fill = rmse_test_type)) +
geom_bar(stat = "identity", position = position_dodge()) +
geom_text(aes(label = round(RMSE, digits = 4)),
position = position_dodge(width = 0.9), vjust = -0.2) +
theme_minimal() +
theme(axis.title = element_blank(),
legend.title = element_blank(),
legend.position = "top") +
scale_fill_manual(values = c("gray30","red"))
Yararlandığım Kaynaklar:
Stokastik Süreçler ve R Uygulamaları; G.Ö.Kadılar
Biyoenformatik DNA Mikrodizi Veri Madenciliği; Ç.S.Erol, Y.Özkan