import pandas as pd
import datetime as dt
import praw
from nltk.sentiment.vader import SentimentIntensityAnalyzer as SIA
import matplotlib.pyplot as pltGiriş
Reddit, kullanıcıların çeşitli konularda haberleri tartıştığı ve paylaştığı popüler bir platformdur. Bu blog yazısında, Reddit’in en çok takip edilen haber topluluklarından biri olan r/worldnews subreddit’inde paylaşılan başlıkların duygu analizini gerçekleştireceğiz. Amacımız, kullanıcıların dünya olaylarına dair duygusal tepkilerini anlamak ve bu tepkilerin zaman içerisindeki değişimini incelemektir.
Kullanılacak Kütüphaneler
Uygulamanın Oluşturulması
Reddit platformundan verileri çekebilmek için öncelikle buradan bir uygulama oluşturarak OAuth2 anahtarlarını almamız gerekiyor ki API’a ulaşabilelim.
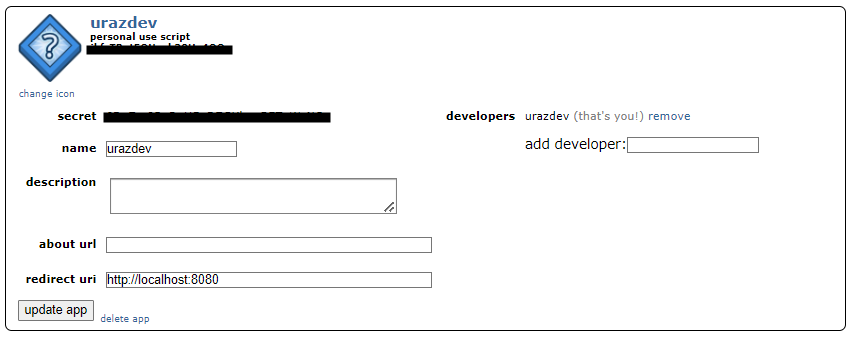
Adım 1. are you a developer? create an app... butonuna tıklayalım.
Adım 2. name alanına kullanıcı ismimizi yazalım, script’i seçelim ve redirect uri alanına http://localhost:8080 bilgisini girelim.
Adım 3. create app butonuna tıklayalım.
Bize verilen personal use script ve secret bilgilerini kullanacağız.
Subreddit Başlıklarının Çekilmesi
praw kütüphanesini kullanarak Reddit API’ına erişim sağlıyoruz.
reddit = praw.Reddit(
client_id='personel_use_script',
client_secret='secret',
user_agent='username'
)topics_dict isimli bir sözlük oluşturalım. Bu sözlük çekmek istediğimiz bilgileri içerecek.
topics_dict = {
'id':[],
'title':[],
'score':[],
'comms_num':[], # kullanmayacağız ama kalsın
'created':[]
}Verileri r/worldnews isimli subreddit’ten çekeceğiz ve sözlüğü veri çerçevesine dönüştüreceğiz.
for submission in reddit.subreddit('worldnews').new(limit=None):
topics_dict['id'].append(submission.id)
topics_dict['title'].append(submission.title)
topics_dict['score'].append(submission.score)
topics_dict['comms_num'].append(submission.num_comments)
topics_dict['created'].append(submission.created)
topics_df = pd.DataFrame(topics_dict)
Tarih ve saat bilgisi timestamp formatındaki created kolonunda yer almaktadır. Bunu datetime formatına dönüştürmemiz gerekiyor.
def timestamp_to_datetime(created):
return dt.datetime.fromtimestamp(created)
topics_df['datetime'] = topics_df['created'].apply(timestamp_to_datetime)
Duygu Skorlarının Elde Edilmesi ve Verilerin Görselleştirilmesi
sia = SIA()
results = []
for datetime, line, score in zip(topics_df['datetime'], topics_df['title'], topics_df['score']):
pol_score = sia.polarity_scores(line)
pol_score['datetime'] = datetime
pol_score['headline'] = line
pol_score['score'] = score
results.append(pol_score)
results_df = pd.DataFrame.from_records(results)
Yukarıda, öncelikle SIA (SentimentIntensityAnalyzer) isimli duygu analizi aracını kullanabilmek için bir nesne oluşturduk. Sonrasında her bir başlığın duygu analizini yapmak için SIA’in polarity_scores metodunu kullandık. Bu metot, bir metnin duygusal içeriğini analiz eder ve dört farklı duygu ölçüsü verir: pos (olumlu), neg (olumsuz), neu (nötr) ve compound (bileşik, tüm duyguların birleşimi). Biz compound ile ilgileneceğiz. Tüm bilgileri daha önce boş bir liste olarak oluşturduğumuz results değişkenine gönderdik ve döngü bittikten sonra results listesini results_df isimli veri çerçevesine dönüştürdük.
Görselleştirmeyi iki farklı şekilde yapabiliriz.
Birincisi, Reddit skorları (beğeni) ile duygu skorlarını gösterebiliriz. Şu an gündemde olduğu için başlıklarda geçen Iran veya Israel için farklı bir renk tercih edebiliriz.
plt.figure(figsize=(10,6))
plt.scatter(results_df['compound'], results_df['score'], alpha=.1, color='gray', label='Other Headlines')
for index, row in results_df.iterrows():
if 'Iran' in row['headline'] or 'Israel' in row['headline']:
plt.scatter(row['compound'], row['score'], color='red')
plt.xlabel('Compound Sentiment Score')
plt.ylabel('Reddit Score')
plt.title('r/worldnews: Sentiment Score vs. Reddit Score')
plt.grid(True)
plt.yscale('log')
plt.legend(['Other Headlines', 'Headlines containing Iran or Israel'])
plt.show()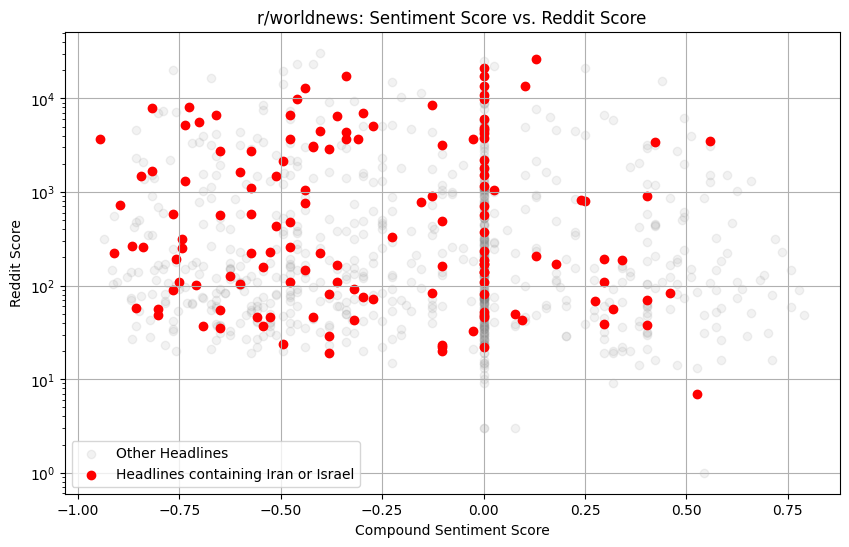
İkincisi, duygu skorlarının ortalamada nasıl değiştiğini bir zaman serisi olarak gösterebiliriz.
results_df['date'] = results_df['datetime'].dt.date
daily_avg_compound = results_df.groupby('date')['compound'].mean()
plt.figure(figsize=(10,6))
plt.plot(daily_avg_compound.index, daily_avg_compound, marker='o', markersize=8, color='r')
plt.ylabel('Daily Average Compound Score')
plt.title('r/worldnews: Daily Average Compound Score over Time')
plt.grid(True)
plt.show()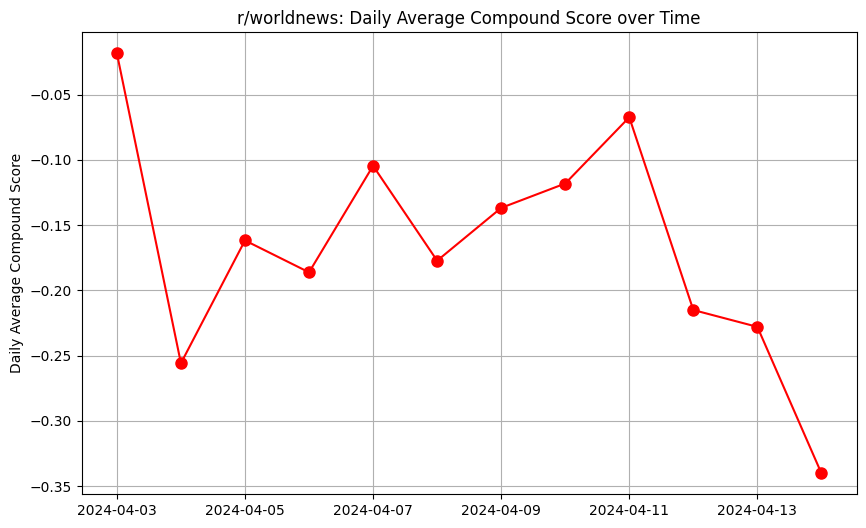
Gelecek içeriklerde görüşmek dileğiyle.